
 Nikke Rose
Nikke Rose
Movement Is the New GTM Metric for Agentic Workflows
Agentic GTM Workflows: The Real Advantage Is Movement, Not More Activity In the AI era, GTM teams can generate more content, leads, signals, and...




Real GTM. Smarter Revenue.
RevAI Real Talk™ is where B2B GTM leaders get clear, practical perspectives on what it actually takes to modernize revenue in the AI era. We break down Revenue AI, Human-Agentic GTM Organizational Design, ABM/ABX, RevOps, outbound, buying groups, data trust, and GTM operating systems to drive scalable, predictable growth — without hype, fluff, or vendor-spin. Subscribe to the feed.
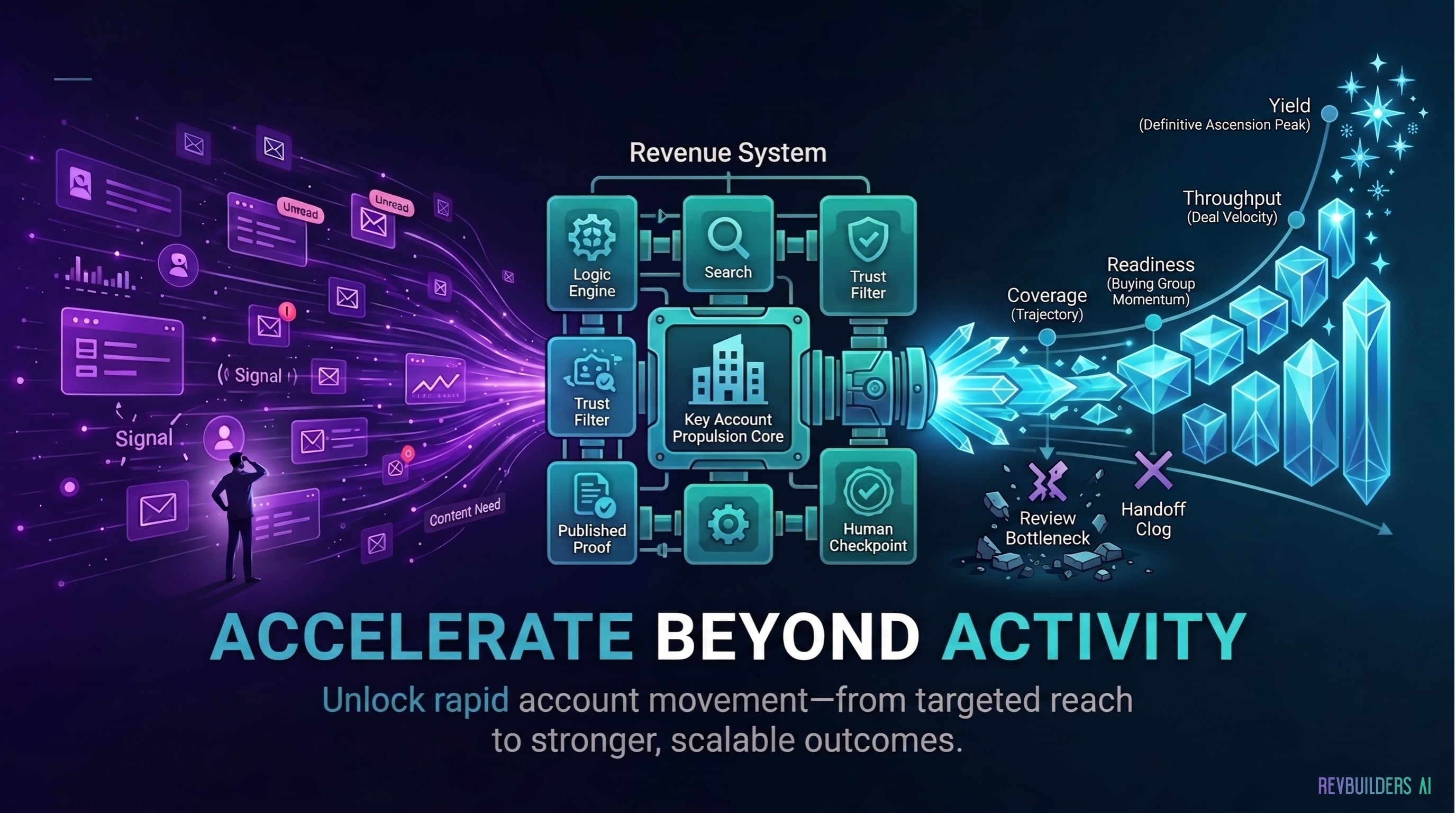
Agentic GTM Workflows: The Real Advantage Is Movement, Not More Activity In the AI era, GTM teams can generate more content, leads, signals, and...

What going deep into a human-agentic GTM operating model revealed about humans, agents, systems, and revenue trust

Who reads your email first — the buyer or AI?